Back to all episodes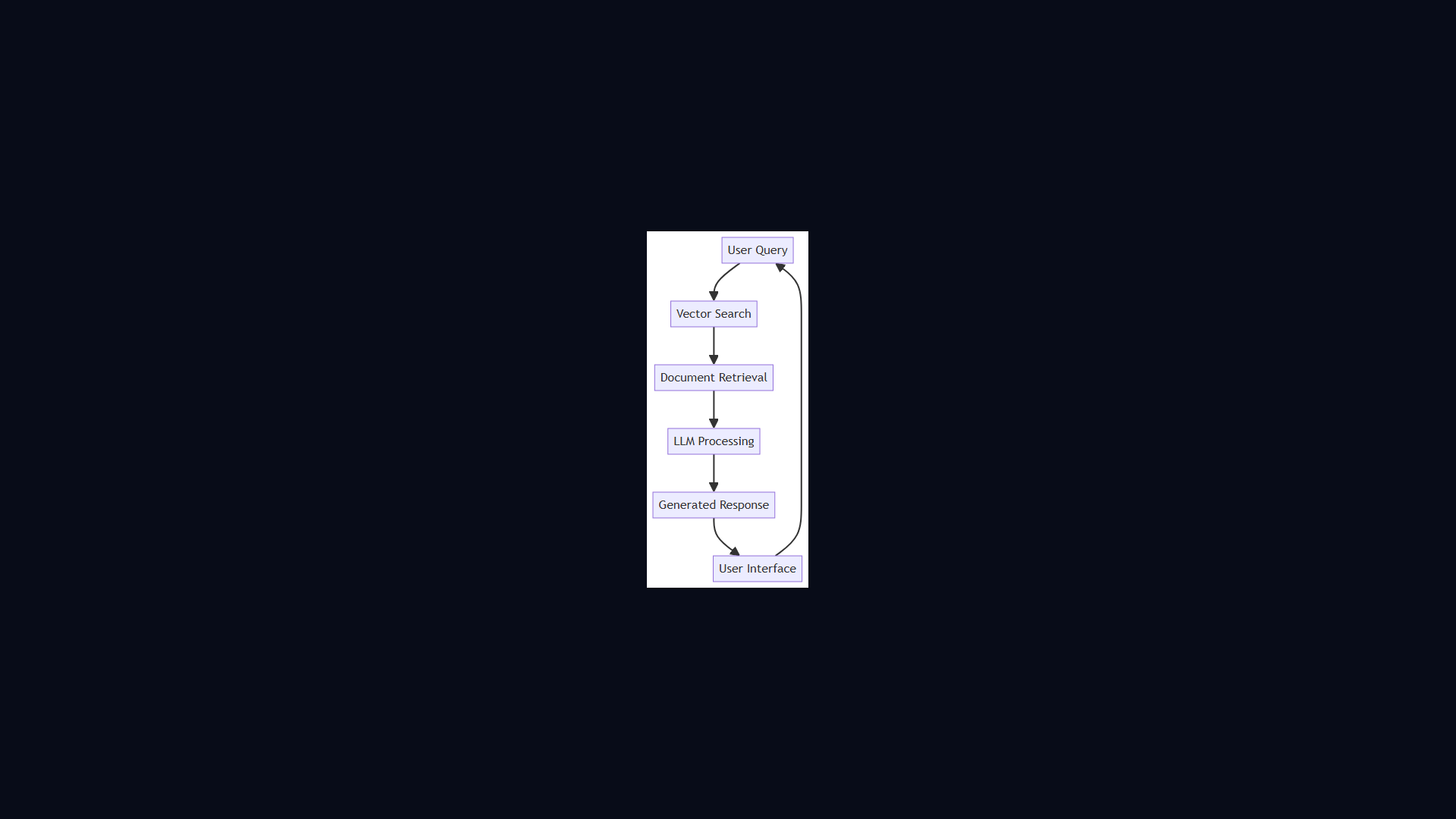
Episode 22LLM & AIFREE
RAG Pipeline Architecture
4:46 · Alex & Sam
OpenAIPineconeLangChain#rag#retrieval#embeddings#vector-search#llm
Show Notes
Retrieval-Augmented Generation lets LLMs answer questions about your private data without retraining. Alex and Sam walk through chunking, embedding, vector search, and context stuffing.
Key Takeaways
- Alex and Sam walk through chunking, embedding, vector search, and context stuffing.
- Core concepts covered: Rag, Retrieval, Embeddings, and 2 more.
- Key trade-offs and design decisions you can apply to your own system design interviews.
Read the full article
RAG Pipeline Architecture — deep dive with diagrams, tradeoffs & interview questions
Architecture Diagram