Back to all episodes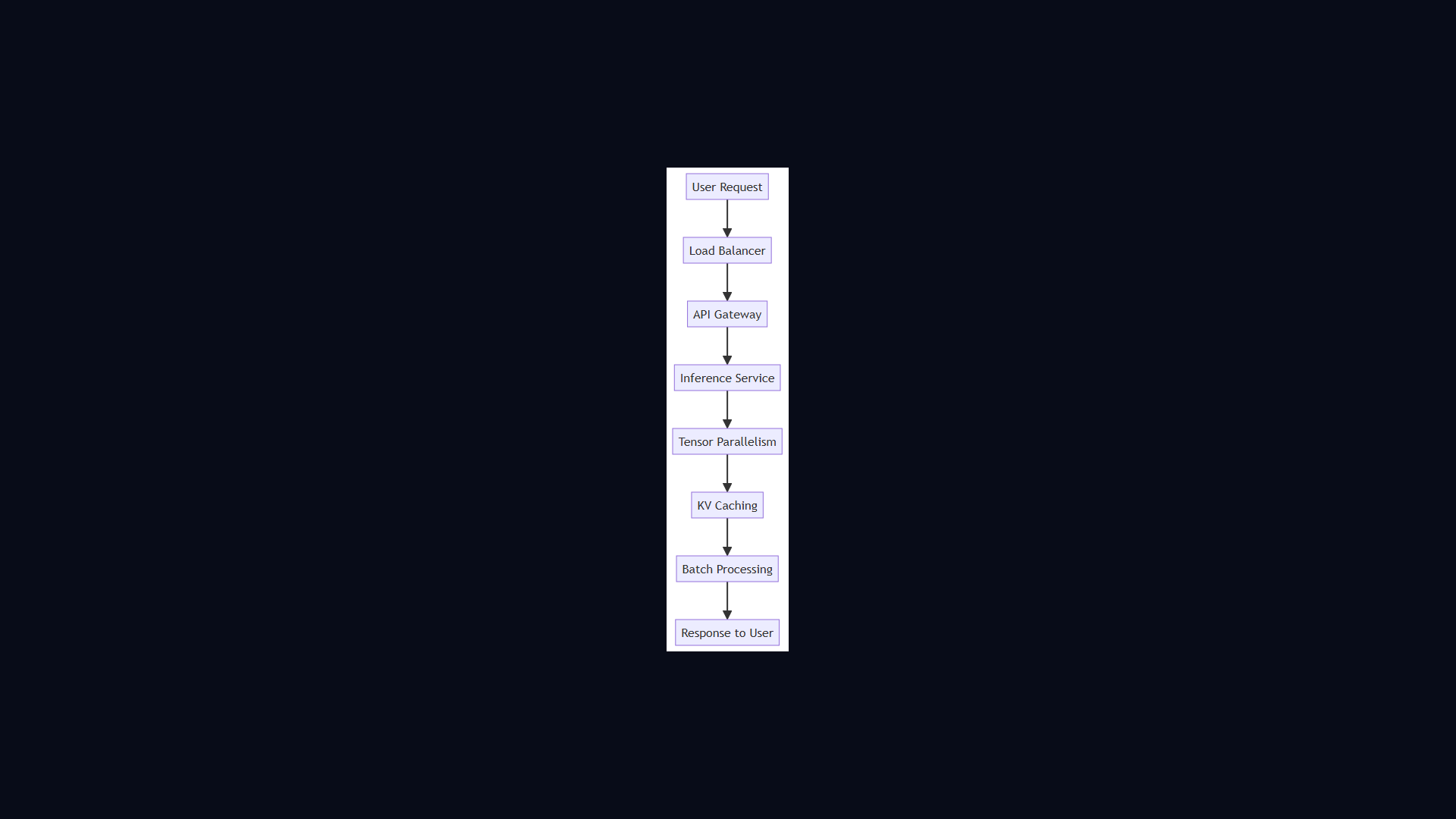
Episode 21LLM & AIFREE
GPT Inference Architecture
4:08 · Alex & Sam
OpenAI#gpt#inference#kv-cache#tensor-parallelism
Show Notes
Serving GPT-4 to millions of users concurrently requires a novel approach to batching and memory. Sam and Alex cover KV caching, continuous batching, tensor parallelism, and flash attention.
Key Takeaways
- Sam and Alex cover KV caching, continuous batching, tensor parallelism, and flash attention.
- Core concepts covered: Gpt, Inference, Kv Cache, and 1 more.
- Key trade-offs and design decisions you can apply to your own system design interviews.
Read the full article
GPT / Transformer Inference Architecture — deep dive with diagrams, tradeoffs & interview questions
Architecture Diagram