Back to all episodes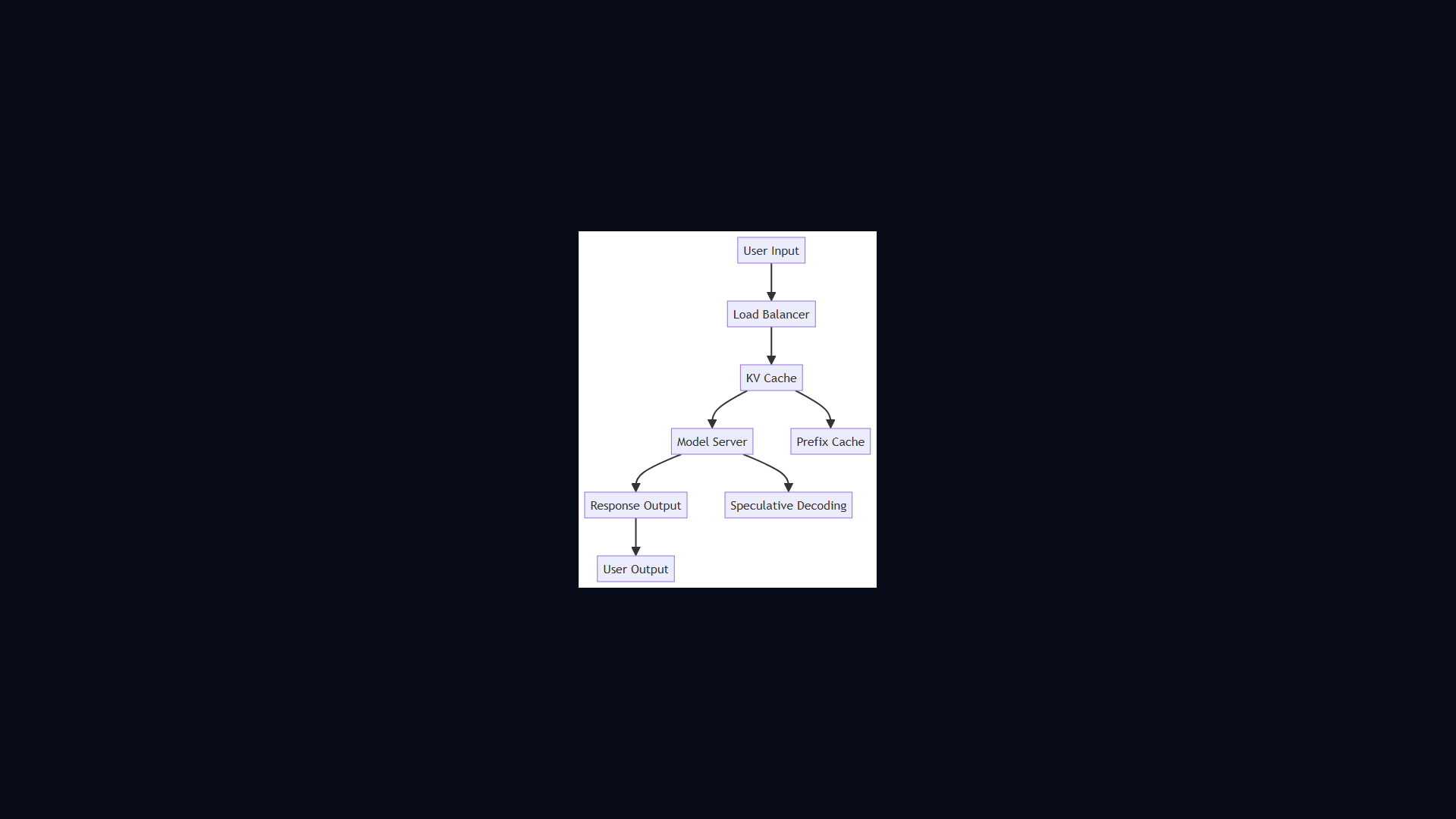
Episode 27LLM & AIFREE
Prompt Caching & KV Cache
4:14 · Alex & Sam
AnthropicOpenAI#prompt-caching#kv-cache#cost-reduction#latency
Show Notes
Caching prompt prefixes can cut LLM costs by 90%. Sam and Alex explain the KV cache, prompt caching in Anthropic's Claude API, and how to architect applications to benefit.
Key Takeaways
- Sam and Alex explain the KV cache, prompt caching in Anthropic's Claude API, and how to architect applications to benefit.
- Core concepts covered: Prompt Caching, Kv Cache, Cost Reduction, and 1 more.
- Key trade-offs and design decisions you can apply to your own system design interviews.
Read the full article
Prompt Caching & KV Cache Architecture — deep dive with diagrams, tradeoffs & interview questions
Architecture Diagram