Back to all episodes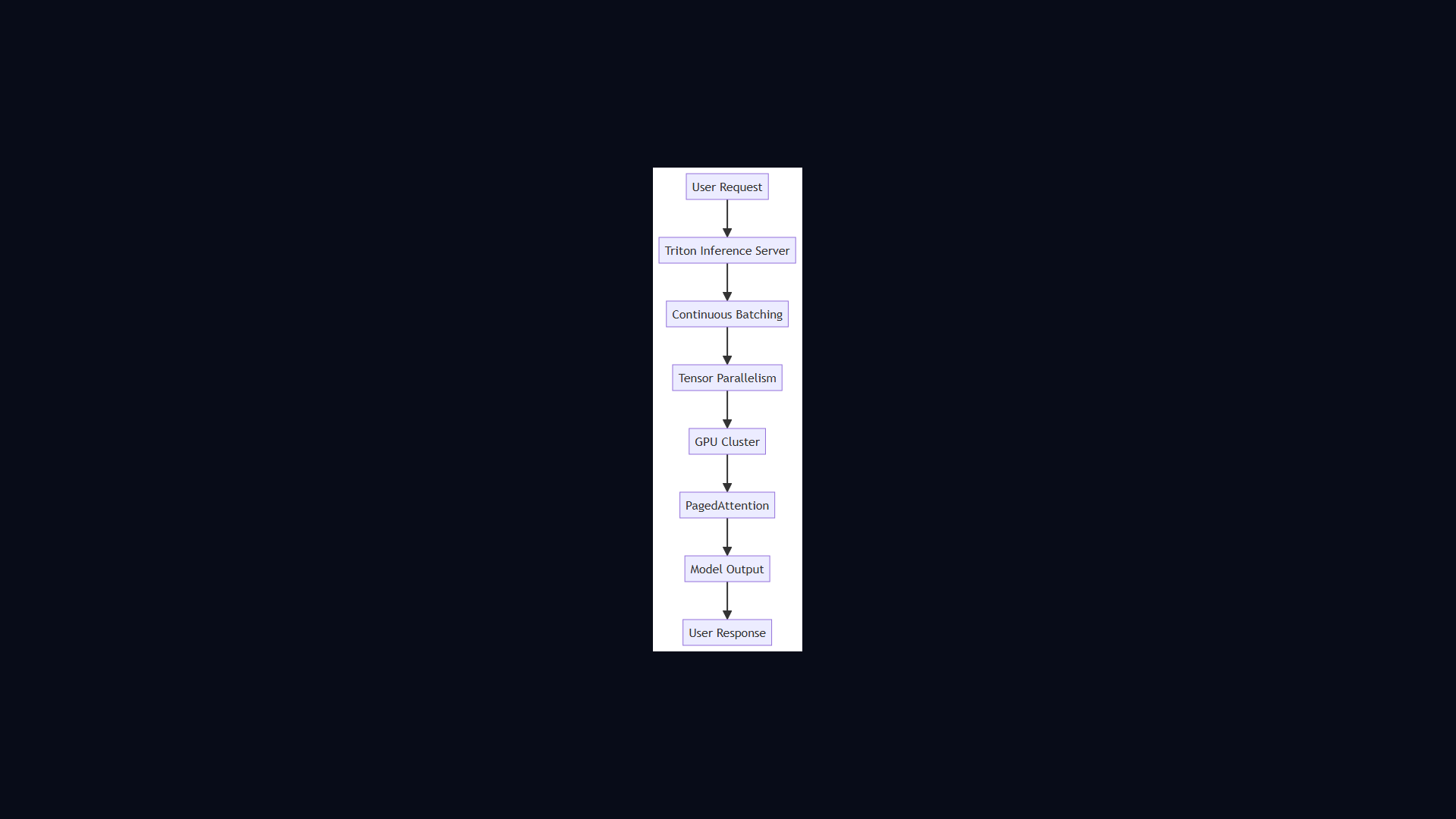
Episode 30LLM & AIFREE
LLM Serving Infrastructure
5:03 · Alex & Sam
vLLMNVIDIAAWS#vllm#paged-attention#speculative-decoding#gpu-cluster
Show Notes
Serving LLMs at scale requires purpose-built infrastructure. Alex and Sam discuss vLLM, PagedAttention, speculative decoding, and how cloud providers think about GPU cluster scheduling.
Key Takeaways
- Alex and Sam discuss vLLM, PagedAttention, speculative decoding, and how cloud providers think about GPU cluster scheduling.
- Core concepts covered: Vllm, Paged Attention, Speculative Decoding, and 1 more.
- Key trade-offs and design decisions you can apply to your own system design interviews.
Read the full article
LLM Serving Infrastructure — deep dive with diagrams, tradeoffs & interview questions
Architecture Diagram